5月20日,Nature子刊《Nature Communications》在線發表了重慶大學大數據與軟件學院曾遠松團隊研究論文,“CellFM: a large-scale foundation model pre-trained on tran omics of 100 million human cells”,開發了當前全球最大的單細胞基礎模型。
單細胞測序技術的飛速發展,帶來了海量數據,也伴隨噪聲、稀疏性和批次效應等挑戰。如何使用統一的框架最大程度地利用這些數據,成為領域里亟待解決的問題。大語言模型(LLM)如ChatGPT等,已經在多個領域展現了強大的泛化能力,這為單細胞大語言模型的誕生提供了靈感。然而,現有的單細胞大模型大多受限于數據規模,性能難以突破瓶頸。
曾遠松(第一作者兼第一通訊)聯合中山大學、華為、新格元兩家各領域龍頭公司共同研發的單細胞基礎大模型 CellFM 正式發表在 Nature Communications 雜志上。該模型基于超1億個人類細胞進行訓練(數據規模為同類模型的兩倍以上),并依托廣州超算中心的強大計算資源與華為昇騰芯片的高效算力,構建了一個超過8億參數的模型,參數規模達同類模型的8倍以上。

億級人類細胞數據×8億參數:CellFM引領單細胞大模型升級
目前,面向單一物種的單細胞轉錄組大模型大多基于千萬級細胞數據進行訓練,模型的泛化能力和對復雜生物過程的表征能力仍存在一定局限。為此,研究團隊收集了公開的人類單細胞轉錄組開源數據,經過篩選、清洗、均一化等預處理流程,建立了目前已知最大規模的超過1億細胞的高質量訓練數據集;通過利用這些多樣化的單細胞數據集,研究團隊開發了一個具有8億參數的模型CellFM(圖1),這在規模和能力上是一個顯著的飛躍,使其比當前的單一物種LLMs大8倍。CellFM的核心是ERetNet,這是一種為效率和性能而設計的Transformer架構變體,使研究團隊的模型能夠輕松處理龐大且復雜的數據集。研究團隊的實驗表明,CellFM在包括細胞注釋、擾動預測和基因功能預測在內的各種單細胞下游應用中,性能超過了現有模型。隨著單細胞RNA測序領域的不斷發展,研究團隊的工作有望激發科學界及更廣泛領域的想象力。
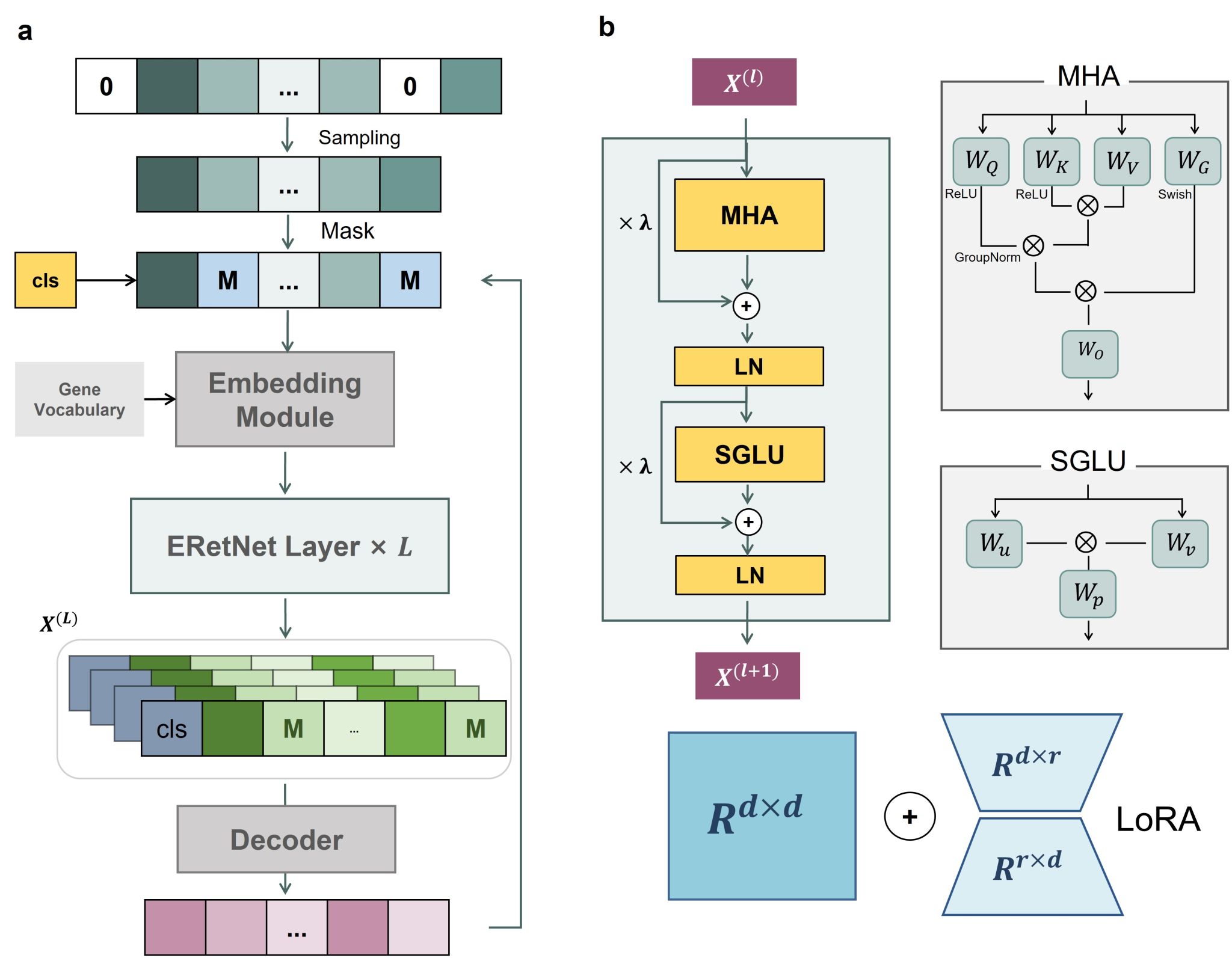
圖1 CellFM模型圖
CellFM賦能高精度基因功能預測
基因功能預測是生命科學研究的基礎。傳統的生物學研究需要大量實驗,而CellFM大模型通過虛擬預測,能夠快速鎖定功能靶點,依靠“計算先行、實驗驗證”,構建AI for Science高效研究新范式。CellFM可以對不同生物學功能的基因進行準確分類,在三種二分類問題中準確率(Accuracy,縮寫ACC)都位列第一,如劑量敏感性任務取得最佳的ACC,較UCE和scGPT分別提升5.68%和5.86%,且UMAP可視化顯示出更清晰的基因簇分布。
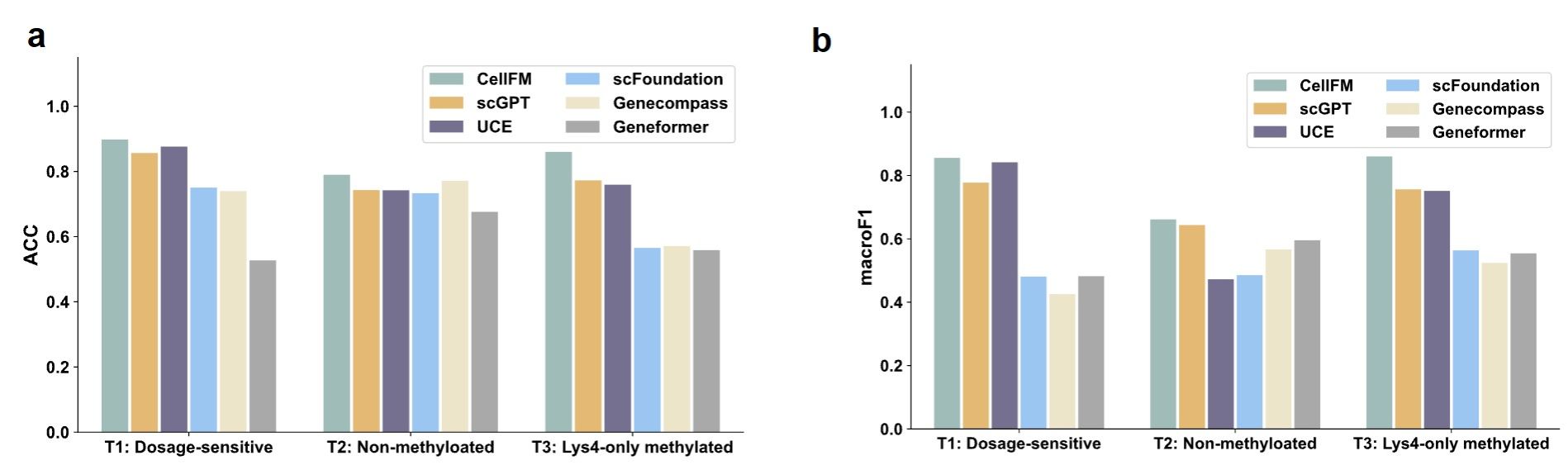
圖2 各模型在3種基因功能二分類任務中的ACC對比。CellFM在3種任務中都獲得了最高的ACC。
CellFM助力靶點預測與擾動響應模擬
CellFM能夠模擬細胞對基因敲除、過表達或藥物處理的響應,快速篩選潛在的藥物作用或基因調控結果。用CellFM的基因嵌入向量替換經典擾動模型GEARS的嵌入向量,在Adamson和Norman數據集上,差異基因變化的Pearson相關系數在所有對比模型中最優。CellFM還能夠根據擾動反向預測靶點基因,例如基于疾病樣本中的異常細胞,逆推出可能導致該表型的關鍵基因或藥物靶點。CellFM反向擾動預測的Top10命中率達81.8%,比scGPT高18.1%;且Top3命中率達到了scGPT的2倍,顯著提升尋找靶點基因的效率。
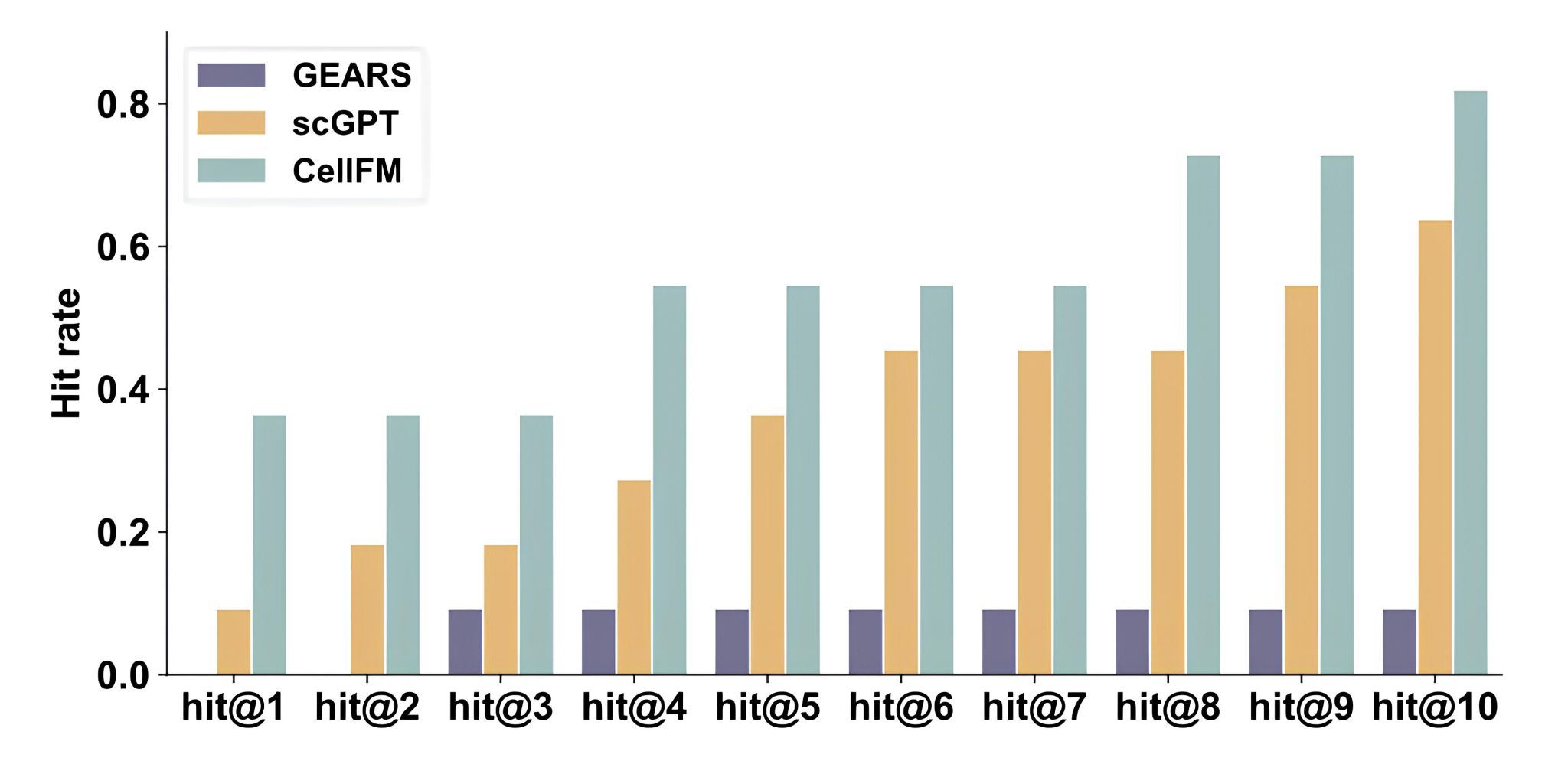
圖3 各模型擾動靶點基因預測命中率。CellFM的Top1-Top10命中率均領先其他模型。
作者介紹:
曾遠松博士現任重慶大學大數據與軟件學院弘深青年教師,2023年7月博士畢業于中山大學計算機科學與技術學院。曾博長期專注于“人工智能+”單細胞和空間多組學數據分析領域,并在Nature Computational Science、Nature Communications、Communications biology、Bioinformatics等期刊上發表了二十余篇文章。他主持了國家自然科學基金青年項目、國家資助博士后研究人員計劃項目、中國博士后面上項目和中央高校基本科研業務費“基礎與前沿交叉專項”(青年項目)等項目。此外,他還獲得了2024年度ACM SIGBIO China“優博獎”和2024年度川渝科技學術優秀論文二等獎。
論文地址:https://www.nature.com/articles/s41467-025-59926-5
代碼地址:https://github.com/biomed-AI/CellFM
來源:大數據與軟件學院
作者:曾遠松 蒲姝穎
